Ergebnis 1 von ungefähr 4.980.000 für Wie funktioniert eine Suchmaschine?. (10‾¹ Sekunden)
Wie funktioniert eine Suchmaschine?
Wie erhalten Suchmaschinen ihre Daten?
Suchmaschinen sammeln Ihre Daten mit spezieller Software, den "Robots", die ihre Informationen von den Webservern erhalten, bei denen die Webseiten abgelegt sind. Im Gegensatz dazu erhalten Kataloge wie Yahoo oder Web.de ihre Informationen indem die angemeldeten Seiten von Menschen angesehen und beurteilt werden. Eigentlich sind Namen wie Crawler (Kriecher), Spider (Spinne) oder Worm (Wurm) irreführend, weil sie die Vorstellung wecken, dass diese durch das Web wandern, sich dort die Seiten "durchlesen", über Hyperlinks weiterwandern, die nächste Seite lesen, u.s.w.. Die Robots erfahren über die Hyperlinks, wo die nächsten Seiten sind, deren Inhalte auf die Anfragen der Robots an die Suchmaschine übermittelt werden. Ein Robot wandert nicht zwischen den Seiten herum, er stellt lediglich Anfragen, die ihm in Form übermittelter Daten beantwortet werden. Da verhalten sich Robots ähnlich wie Browser. Die hier erwähnten Robots sind den Suchmaschinen zugeordnet. Es gibt noch eine Reihe weiterer Anwendungen die mit Robot-ähnlichen Programmen arbeiten. Etwa Link-Checker oder Programme die ganz bestimmte Informationen aus Webseiten lesen. Es gibt sehr viele Robots die nicht von grossen Suchmaschinen kommen und sich auch nicht in Logfiles eintragen. Diese werden hier aber nicht betrachtet. Robots der Suchmaschinen tragen sich in der Regel in die Logfiles der Domain ein. Die Eintrags-Namen finden Sie jeweils in den @-web-Beiträgen zu den einzelnen Suchmaschinen. Eine Übersicht diverser aktiver Robots gibt es unter: robotstxt.org
Für Suchmaschinen sind zwei Wege populär, um Webseiten zu erfassen:
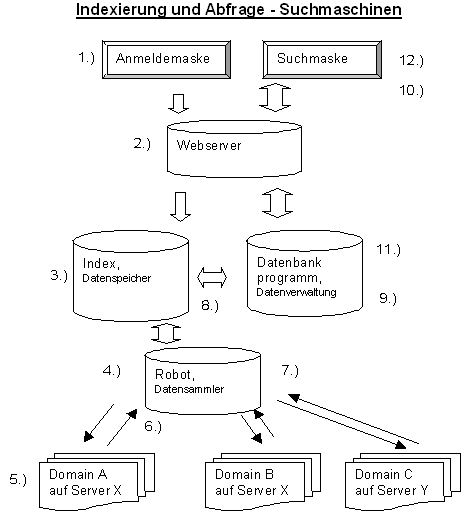
In der folgenden Darstellung ist der prinzipielle Weg dargestellt, wie eine Datei in die Datenbank einer Suchmaschine aufgenommen wird (1. bis 9.). Die Punkte 10. bis 12. beschreiben die Abfrage der Suchmaschinen-Datenbank. Die Darstellung hat sehr allgemeinen Charakter und kann je nach Suchmaschine sehr unterschiedlich aussehen. Die Darstellung der Google-Suchmaschine und ihrer Bestandteile z.B. würde wesentlich komplexer ausfallen. Es soll hier lediglich zum allgemeinen Verständnis für die verschieden Elemente der Suchmaschine beigetragen werden. In welchem Umfang die Elemente Indexer, Robot und Datenbank als getrennte Komponenten betrieben werden, hängt in erster Linie vom Umfang der Suchmaschine ab.
Erläuterung:
Anmerkung: Obige Darstellung ist schon einige Jahre alt. Bedeutende Suchmaschinen sind heute viel komplexer.
« zurück «
Suchmaschinen sammeln Ihre Daten mit spezieller Software, den "Robots", die ihre Informationen von den Webservern erhalten, bei denen die Webseiten abgelegt sind. Im Gegensatz dazu erhalten Kataloge wie Yahoo oder Web.de ihre Informationen indem die angemeldeten Seiten von Menschen angesehen und beurteilt werden. Eigentlich sind Namen wie Crawler (Kriecher), Spider (Spinne) oder Worm (Wurm) irreführend, weil sie die Vorstellung wecken, dass diese durch das Web wandern, sich dort die Seiten "durchlesen", über Hyperlinks weiterwandern, die nächste Seite lesen, u.s.w.. Die Robots erfahren über die Hyperlinks, wo die nächsten Seiten sind, deren Inhalte auf die Anfragen der Robots an die Suchmaschine übermittelt werden. Ein Robot wandert nicht zwischen den Seiten herum, er stellt lediglich Anfragen, die ihm in Form übermittelter Daten beantwortet werden. Da verhalten sich Robots ähnlich wie Browser. Die hier erwähnten Robots sind den Suchmaschinen zugeordnet. Es gibt noch eine Reihe weiterer Anwendungen die mit Robot-ähnlichen Programmen arbeiten. Etwa Link-Checker oder Programme die ganz bestimmte Informationen aus Webseiten lesen. Es gibt sehr viele Robots die nicht von grossen Suchmaschinen kommen und sich auch nicht in Logfiles eintragen. Diese werden hier aber nicht betrachtet. Robots der Suchmaschinen tragen sich in der Regel in die Logfiles der Domain ein. Die Eintrags-Namen finden Sie jeweils in den @-web-Beiträgen zu den einzelnen Suchmaschinen. Eine Übersicht diverser aktiver Robots gibt es unter: robotstxt.org
Für Suchmaschinen sind zwei Wege populär, um Webseiten zu erfassen:
- Anmelden des HTML-Dokument auf der Anmeldeseite der Suchmaschine, manuell durch den Websitebetreiber oder von ihm beauftragte Dienstleister.
- Verfolgen der Links angemeldeter Seiten, nachdem sie von der Software erfasst und ausgewertet wurden, automatisch durch die Suchprogramme.
In der folgenden Darstellung ist der prinzipielle Weg dargestellt, wie eine Datei in die Datenbank einer Suchmaschine aufgenommen wird (1. bis 9.). Die Punkte 10. bis 12. beschreiben die Abfrage der Suchmaschinen-Datenbank. Die Darstellung hat sehr allgemeinen Charakter und kann je nach Suchmaschine sehr unterschiedlich aussehen. Die Darstellung der Google-Suchmaschine und ihrer Bestandteile z.B. würde wesentlich komplexer ausfallen. Es soll hier lediglich zum allgemeinen Verständnis für die verschieden Elemente der Suchmaschine beigetragen werden. In welchem Umfang die Elemente Indexer, Robot und Datenbank als getrennte Komponenten betrieben werden, hängt in erster Linie vom Umfang der Suchmaschine ab.
Erläuterung:
- In der Anmeldemaske der Suchmaschine werden HTML-Dokumente angemeldet. In der Regel ist das die Startseite einer Webpräsenz. Mitunter ist es ratsam, einzelne Seiten anzumelden wenn diese schnell in die Datenbank aufgenommen werden sollen. Anmeldemaske und Suchmaske gehören zum Webserver der auch die Ergebnislisten anzeigt.
- Der Webserver dient als Schnittstelle zum Datenbankprogramm.
- URL wird in den Indexer aufgenommen. Diverse Filter gegen Spam und gegen unsaubere Inhalte sorgen für aufbereitete Daten. Gesperrte Adressen werden ebenfalls ausgefiltert. Einige Suchmaschinen setzen ausserdem auf redaktionelle Auslese. In der Praxis gibt es allerdings mit dem Filtern Probleme, wie man leicht in den Ergebnislisten feststellen kann. Bei vielen Suchmaschinen dauert der Aufnahmevorgang nur wenige Tage. Leistungsfähige Suchmaschinen übertragen die angemeldeten Seiten innerhalb von 24 Stunden in die Datenbank. Bevor die Daten der angemeldeten Seite in die Datenbank übertragen werden können, muss ein Abfragezyklus bis Pkt. 8 durchlaufen werden. In der Regel wird sofort bei der Anmeldung überprüft, ob die URL überhaupt vorhanden (erreichbar) ist.
- Der Datensammler wird oft als Robot, Spider oder Crawler bezeichnet. Der Robot ist ein Programm, das Anfragen in das WWW an die Server des jeweiligen Hoster sendet. Es sorgt für die Aufnahme der Daten aus dem WWW in die Suchmaschine. Er browst die Links ab und parst die Webseiten um die Daten für den Index herauszulesen. Startpunkt für Robots sind in der Regel URL-Listen, die dadurch entstehen, dass die Startseite einer Webpräsenz angemeldet wird. Erweitert werden diese Listen durch Links, die beim Erfassen der Webseiten ermittelt werden. Alle laufenden URL-Anmeldungen werden überwiegend in den ruhigen Nachtstunden abgefragt und geladen. Google aktualisiert innerhalb von 4 Wochen viel mehr als 8 Milliarden Webseiten. Da muss der Robot schnell arbeiten und darf dennoch nicht zu schnell sein. Es kann vorkommen, dass viele der abzufragenden Dokumente auf einem Server (ein oder mehrere Rechner die viele Domains beherbergen) eines Internet-Provider gespeichert sind. Ein Robot kann sehr viele Abfragen parallel ausführen. Ein ungeschriebenes Gesetz besagt, dass die Abfragen dem Server nicht mehr als ein Prozent der Systemressourcen abverlangen sollen, damit die Antwortzeiten des Server für die normalen Browser-Abfragen auf einem verträglichen Niveau bleiben.
- Die Darstellung der Domains ist rein symbolisch. Die unglaubliche Vielzahl der abzufragenden Domains lässt sich hier nicht darstellen. Der Webserver beantwortet die Abfrage. Mit einer speziellen Datei, robots.txt und den robots Meta-Tags, sollte jeder Betreiber einer Website bestimmen können welche Robots auf seine Seiten zugreifen dürfen. Ob sich die Robots tatsächlich daran halten, hängt von ihrer Programmierung ab. Die Praxis zeigt, dass es Robots gibt die derartige Festlegungen nicht beachten. Es lassen sich auch einzelne Verzeichnisse ( /privat) ausschliessen. Werden Dateien oder Verzeichnisse mit einem serverseitigen Zugriffsschutz (Passwort) versehen, können diese nicht erfasst werden.
- Die angeforderte(n) Datei(en) wird übertragen. In der Regel werden für eine Webseite mehrere Dateien übertragen, da ein HTML-Dokument meist noch weitere Elemente wie Bilder, Grafiken oder Sound enthält. Wird eine Web-Seite nicht gefunden, erhält der Index die Mitteilung, dass die Datei nicht mehr vorhanden ist. Diese wird dann (bei einigen Suchmachinen) aus dem Index gelöscht. Nach diesem Prinzip können Dateien manuell aus der Datenbank der Suchmaschine entfernt werden. Sie melden der Suchmaschine die URL, an der sich die Datei befand. Ein Robot wird ausgesandt um die Datei zu indexieren. Die Suchmaschine erhält vom Robot die Information Datei nicht gefunden (Fehlermeldung 404). Alle URL's mit diesem Statuscode werden nach einigen Tagen automatisch aus dem Index gelöscht.
- Die Daten werden vom Robot erfasst und zum Index weitergeleitet. Aus den Daten, die der Robot auf die Anfrage erhält, parst er die Links und alle für die Suchmaschinen wichtigen Informationen. Er sendet weitere Anfragen an den Server und erhält als Antwort wiederum neue Daten. Dieser Vorgang läuft solange, bis alle Daten abgefragt wurden, oder eine Zeitbeschränkung den Vorgang beendet.
- Das Indexierungsprogramm wertet die ihm übermittelten Daten aus. Es werden nur die Daten aufgenommen, die in der Datenbank eine entsprechende Rubrik bekommen.
Der Inhalt eines Suchmaschinenindex wird durch seine Nutzer gestaltet. Mit Ihrem Seiteninhalt und der Gestaltung von Titel und Metatags sorgen Sie dafür, wie die
Inhalte dargestellt werden. Der unsichtbare Teil einer Webseite enthält den Meta-Tag Keywords, der von den meisten Suchmaschinen jedoch nicht ausgewertet wird, da
er zu viel Missbrauchpotential bieten. Der Umfang der aufzunehmenden Daten ist bei jeder Suchmaschine unterschiedlich. Volltextsuchmaschinen wie Google, Yahoo! und
Seekport werten den gesamten Text einer Webseite aus, andere begnügenten sich mit den ersten Sätzen einer Webseite. In folgende Kategorien der Datenspeicherung konnten
früher Suchmaschinen eingeteilt werden:
- Volltextsuchmaschinen: u.a. sind Volltextsuche und Phrasensuche möglich
- Speichern v. Meta-Daten als Verschlagwortung: Suche in Verschlagwortung
- Speichern von Wort-Statistiken: Stichwortsuche
- Das Datenbankprogramm verwaltet die Daten der Datenbank. Es verarbeitet die Anfragen der Benutzer und bereitet die Daten für die Anzeige im Webserver auf.
- Wenn Sie eine Suchanfrage in die Eingabe-Maske eingeben, wird die Anfrage in eine computerverwertbare Form umgewandelt und an die Datenbank übermittelt. Empfehlenswert ist es, in der Abfrage möglichst genau zu formulieren, dann wird die Treffermenge kleiner und genauer. In der einfachen Suche ist die Phrasensuche oder eine mehrfache UND-Verknüpfung nützlich. Die erweiterte Suche (oder Profisuche) stellt wesentlich umfangreichere Möglichkeiten wie die Nutzung boolescher Operatoren, Feldsuche usw. zur Verfügung. Alle wichtigen Suchmaschinen haben in der Standardsuche die UND-Suche voreingestellt.
- Das Datenbankprogramm stellt gemäss der Anfrage die Suchergebnisse mit den Daten aus dem Index zusammen. Es werden die jeweiligen Rankingkriterien berücksichtigt.
- Ausgabe der Ergebnisse. Die Darstellungform hängt stark vom Suchsystem ab. In der Regel werden Dokumententitel sowie der Inhalt des Metatag Description,
die ersten Zeilen des Dokumentes, Textausschnitte aus dem sichtbaren Seitentext oder auch die Beschreibung aus dem ODP zur Website, dargestellt. Die Ergebnisse
werden Ihnen in einer, von der Software festgelegten, Reihenfolge präsentiert (Ranking). Bei einigen Suchmaschinen lassen sich die Ergebnisse (z.B. nur Dateien
von dieser Domain) nachträglich sortieren. In der erweiterten Suche finden Sie oftmals Möglichkeiten, das Ranking nach Ihren eigenen Gesichtspunkten zu beeinflussen.
Mit dieser Darstellung soll deutlich werden:
- Web-Dokumente werden nie direkt während der Suchmaschinenabfrage aufgerufen, sondern nur deren Abbild, die zu diesem Dokument gespeicherten Daten in der Datenbank der Suchmaschine.
- Robots stellen lediglich Abfragen und werten die vom Server übermittelten Informationen aus. Sie wandern nicht durch das Netz.
- Suchmaschinen erfassen den gesamten sichtbaren Seitentext sowie weitere Seitenelemente wie Seitentitel, URL und Verweise.
- Eine Suchmaschine deckt in der Regel nur einen Teil des Internet ab und kann deshalb immer nur Informationen liefern, die sie auch in Ihrer Datenbank gespeichert hat. Meta-Sucher, die mehrere Suchmaschinen abfragen, erfassen etwas grössere Teile des Web, liefern dafür aber ungenauere Ergebnisse. Benutzen Sie also ruhig mal eine andere Suchmaschine wenn sie nicht fündig werden!
Anmerkung: Obige Darstellung ist schon einige Jahre alt. Bedeutende Suchmaschinen sind heute viel komplexer.